
大会前
大会前には音声認識エンジンと画像認識ソフトウエアを開発しました。
音声認識エンジン
1.高精度音声認識エンジンの推論時間を短縮することに成功しました! 当初僕達が使っていたDeep Learningを用いた音声認識エンジンKaldiは長い文章でも推論精度は大変良いのですが、推論速度が遅く、ロボカップ@ホームルールの推論制限時間10秒を超えてしまうことがしばしばありました。そこでGPGPUとコンパイル最適化を行い推論時間を5−7秒前後に抑えました。 2.音声認識エンジンを用途別に使い分けることによって推論精度と応答速度の両立に成功しました!
 音声統合クライアントSirius 音声認識エンジンKaldiは短い語彙(例えばMini等)にも5-7秒の推論時間がかかってしまいます。そこで僕達は短い語彙では比較的推論精度が高いPocketSphinx音声認識エンジンと、長い文章でも正確に推論するが推論速度が遅いKaldi音声認識エンジンを、用途に合わせて切り替えるソフトウエアを開発しました。なお音声認識エンジンの切り替えは音声エンジン統合クライアントSiriusが行っています。
音声統合クライアントSirius 音声認識エンジンKaldiは短い語彙(例えばMini等)にも5-7秒の推論時間がかかってしまいます。そこで僕達は短い語彙では比較的推論精度が高いPocketSphinx音声認識エンジンと、長い文章でも正確に推論するが推論速度が遅いKaldi音声認識エンジンを、用途に合わせて切り替えるソフトウエアを開発しました。なお音声認識エンジンの切り替えは音声エンジン統合クライアントSiriusが行っています。
人認識
大会前の僕の担当は人認識ソフトウエアの開発です。 1.ロバストな顔検出ソフトウエアの開発に成功しました! 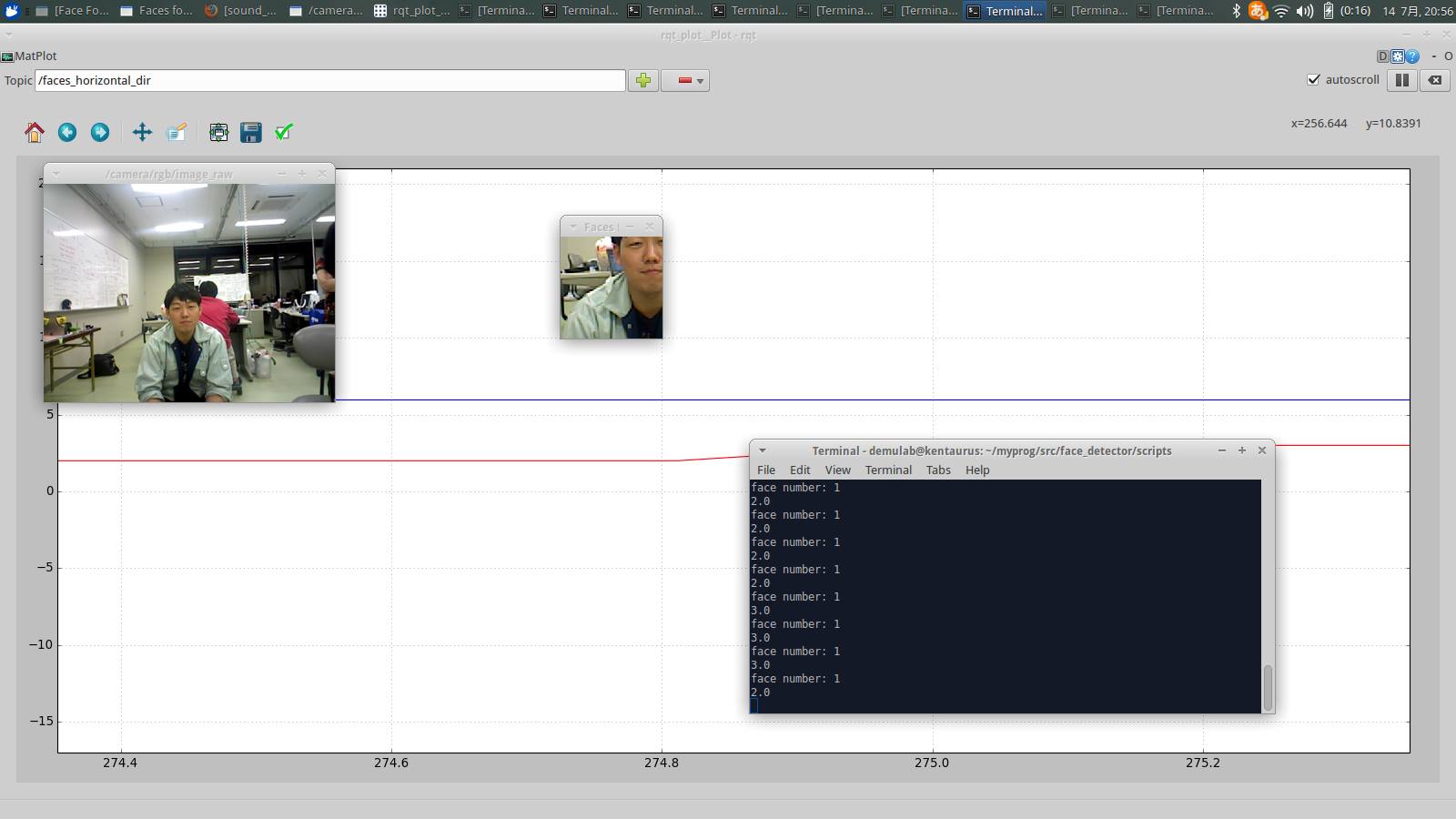 人数のカウント、顔検出は当初HaarCascadeだけで行っていました。なおOpenCVに付属されていた学習済みの検出器を使っていました。 ですがときどき顔でない物体を顔と誤認識することがあります。そこでインターネットから4つ学習済みの顔検出器を取ってきて性能比較しましたが、どれも顔でない物体を顔と誤認識することがしばしばありました。しかし、顔と誤検出する物体はそれぞれ違っていたのでこのHaarCascade検出器をensemble learning(複数の機械学習を組み合わせた機械学習)することができれば誤認識する確率は小さくなるのではと考えました。そこで4つのHaarCascade顔検出器が検出した顔の位置(ピクセル座標)を位置情報からクラスタリング(flat clustering、クラスタの数が自動で決まる階層型クラスタリングアルゴリズム、クラスタリングはコンピューターがデータを自動でグループ化するアルゴリズム)してクラスタの要素が1つだけのものをノイズと判定し除外することによって、正確な顔検出を実現することができました。 2.高精度な性別認識ソフトウエアの開発に成功しました!
人数のカウント、顔検出は当初HaarCascadeだけで行っていました。なおOpenCVに付属されていた学習済みの検出器を使っていました。 ですがときどき顔でない物体を顔と誤認識することがあります。そこでインターネットから4つ学習済みの顔検出器を取ってきて性能比較しましたが、どれも顔でない物体を顔と誤認識することがしばしばありました。しかし、顔と誤検出する物体はそれぞれ違っていたのでこのHaarCascade検出器をensemble learning(複数の機械学習を組み合わせた機械学習)することができれば誤認識する確率は小さくなるのではと考えました。そこで4つのHaarCascade顔検出器が検出した顔の位置(ピクセル座標)を位置情報からクラスタリング(flat clustering、クラスタの数が自動で決まる階層型クラスタリングアルゴリズム、クラスタリングはコンピューターがデータを自動でグループ化するアルゴリズム)してクラスタの要素が1つだけのものをノイズと判定し除外することによって、正確な顔検出を実現することができました。 2.高精度な性別認識ソフトウエアの開発に成功しました!  性別認識は画像からの2値分類問題(コンピューター・数学で性別を判定する関数を求める問題で、分類は2個だけ)と考えることができます。また僕は画像から抽出できる、性別を判定するための低次元特徴量はなく、高次元特徴量しかないと考えました。 そこでこの問題を解くにはDeep Neural Network(現在認識精度が最高の機械学習で多層ニューラルネットワークの発展形)の一種であるConvolutional Neural Networkが向いていると考えました。Convolutional Neural Networkの主なソフトウエアフレームワークにはCaffeがあり、今回はCaffeをNVIDIA GPGPUで高速化したものをバックエンドとするDeep Learning FrameworkのNVIDIA DIGITSを使用しました。 Instagram/twitterの#selfieハッシュタグ等から1ラベル700枚程度、計1400枚程度の画像を14時間かけて手動で収集し(instagramやtwitterはcrawlerを弾きます),3分-45分ほどで1400枚の顔画像をバッチ学習させました。(3分:Nesterov Accelerated Gradient(最急降下法に速度の概念を数学的に定義したことによって高速で学習できるモーメント法をさらに改良して(先に前回のgradientから加速したgradientの演算を行い移動して後から今回のgradientを計算し補正することによって一般のモーメント法より高速で学習できるらしい)学習速度を速くしたアルゴリズム,モーメント法は凸関数だと高速に学習でき,変化の割合が小さい区間を比較的高速に学習し、局所解から抜けることも可能)/AdaGrad(学習率を適応的に調整することによって学習を高速かつ誤差関数の発散を防ぐようにしたアルゴリズム), 45分:Stochastic Gradient Descent(確率的最急降下法、最急降下法はコンピューター・数学で複数のデータを元に関数を自動的に求めるアルゴリズム、確率的最急降下法はランダムに複数のデータを選択しバッチ学習していくことによって局所解に陥るのを防ぐ)) 認識率はvalidation set(交差検証、25%使用)で75%,特に女性の認識率が高かったです。
性別認識は画像からの2値分類問題(コンピューター・数学で性別を判定する関数を求める問題で、分類は2個だけ)と考えることができます。また僕は画像から抽出できる、性別を判定するための低次元特徴量はなく、高次元特徴量しかないと考えました。 そこでこの問題を解くにはDeep Neural Network(現在認識精度が最高の機械学習で多層ニューラルネットワークの発展形)の一種であるConvolutional Neural Networkが向いていると考えました。Convolutional Neural Networkの主なソフトウエアフレームワークにはCaffeがあり、今回はCaffeをNVIDIA GPGPUで高速化したものをバックエンドとするDeep Learning FrameworkのNVIDIA DIGITSを使用しました。 Instagram/twitterの#selfieハッシュタグ等から1ラベル700枚程度、計1400枚程度の画像を14時間かけて手動で収集し(instagramやtwitterはcrawlerを弾きます),3分-45分ほどで1400枚の顔画像をバッチ学習させました。(3分:Nesterov Accelerated Gradient(最急降下法に速度の概念を数学的に定義したことによって高速で学習できるモーメント法をさらに改良して(先に前回のgradientから加速したgradientの演算を行い移動して後から今回のgradientを計算し補正することによって一般のモーメント法より高速で学習できるらしい)学習速度を速くしたアルゴリズム,モーメント法は凸関数だと高速に学習でき,変化の割合が小さい区間を比較的高速に学習し、局所解から抜けることも可能)/AdaGrad(学習率を適応的に調整することによって学習を高速かつ誤差関数の発散を防ぐようにしたアルゴリズム), 45分:Stochastic Gradient Descent(確率的最急降下法、最急降下法はコンピューター・数学で複数のデータを元に関数を自動的に求めるアルゴリズム、確率的最急降下法はランダムに複数のデータを選択しバッチ学習していくことによって局所解に陥るのを防ぐ)) 認識率はvalidation set(交差検証、25%使用)で75%,特に女性の認識率が高かったです。
物体認識
RGB-D画像処理(RGB(通常の画像)とD(深さ情報))で物体認識を行いました。 1. object recognition kitchen  Object Recognition KitchenはWillow GarageがオープンソースでリリースしたRGB-D物体認識ソフトウエアフレームワークです。 僕達は深さ情報からの物体認識にはLINE-MODという高速画像処理アルゴリズムを使用しています。 2. Deep Learning 先ほど人認識で紹介したNVIDIA DIGITSを使用して10000枚の学習した画像をもとに多値分類をしています。
Object Recognition KitchenはWillow GarageがオープンソースでリリースしたRGB-D物体認識ソフトウエアフレームワークです。 僕達は深さ情報からの物体認識にはLINE-MODという高速画像処理アルゴリズムを使用しています。 2. Deep Learning 先ほど人認識で紹介したNVIDIA DIGITSを使用して10000枚の学習した画像をもとに多値分類をしています。
Navigation Test
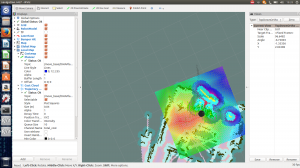 Navigation Testは部屋の決められた複数の場所に障害物にぶつからずに自動でロボットが動く競技です。 僕達はMiniの自律ナビゲーションにgmappingを使用しました。 他のメンバーが15点得点しました。
Navigation Testは部屋の決められた複数の場所に障害物にぶつからずに自動でロボットが動く競技です。 僕達はMiniの自律ナビゲーションにgmappingを使用しました。 他のメンバーが15点得点しました。
Person Recognition Test
 Miniが人を認識して指を指している Person Recognition Testはロボットが人を認識する競技です。 僕が担当しました。競技前にロボットを人の情報を元に駆動系を動かそうと試みたところ、pythonでROSのpublish/subscribeを1つのプログラムで両方行おうとするとスレッド問題で大変苦戦しました。最終的にプログラムの問題で駆動系は動きませんでしたが、性別認識で正解して15点得点しました。全17チーム中無得点チームが8チームである、難易度の高い競技でした。
Miniが人を認識して指を指している Person Recognition Testはロボットが人を認識する競技です。 僕が担当しました。競技前にロボットを人の情報を元に駆動系を動かそうと試みたところ、pythonでROSのpublish/subscribeを1つのプログラムで両方行おうとするとスレッド問題で大変苦戦しました。最終的にプログラムの問題で駆動系は動きませんでしたが、性別認識で正解して15点得点しました。全17チーム中無得点チームが8チームである、難易度の高い競技でした。
Object Recognition Test
Object Recognition Testは物体を認識し、物体をつかみ運ぶ競技です。 他のメンバーが担当しました。認識した物体を示したPDFを競技後提出する必要があるのですが、PDFのフォーマットに間違えて残念ながら得点には至りませんでした。全17チーム中無得点チームが10チームである、難易度が高い競技でした。
Voice Recognition Test
 音声認識で人が選択した50の質問にロボットが答える競技です。他のメンバーが担当しました。固有名詞を元に50問の質問のうち何の質問をしているのか判定しました。 前日では3/5の正解率で100点近く得点することも不可能ではなかったのですが人的な指示ミスで得点は5点になってしまいました。
音声認識で人が選択した50の質問にロボットが答える競技です。他のメンバーが担当しました。固有名詞を元に50問の質問のうち何の質問をしているのか判定しました。 前日では3/5の正解率で100点近く得点することも不可能ではなかったのですが人的な指示ミスで得点は5点になってしまいました。
EGPSR
 自然言語処理ソフトウエアフレームワークNLTK 人の音声命令をロボットが音声認識で判断して、ものを取りにいったり等ロボットがその命令通りに動く競技です。 僕が担当しました。 Kaldi/pocketsphinxの音声認識の推論結果をROSトピック化して、大会時に実装したNLTK(自然言語処理ソフトウエアフレームワーク)とtaggerを用いた英語構文解析、英語照応解析(省略された単語や代名詞を推測するもの)し、音声命令を理解したことを示したことによって20点、全17チーム中5位という高得点を取りました!全17チーム中7チームが無得点である、難易度が高い競技でした。 taggerで単語の品詞を判定することができます。ときどき動詞を名詞と誤判定するので誤判定する部分はルールベースで修正しました。型変換の部分で少し苦労しました。 文章の意味抽出は英語の文型は標準は5つしかないため(SV,SVO,SVC,SVOO,SVOC)構文解析による意味抽出はとても簡単でした。 照応解析については、代名詞や省略が検知された場合、意味を抽出したリストを参照して前後に代名詞の参照元がないか検索するプログラムを製作しました。競技直前まで代名詞に命令を受けているロボット自身を参照する自己参照元(yourself)があることに気づかず、何とか直前に気づきプログラムを修正することができました。
自然言語処理ソフトウエアフレームワークNLTK 人の音声命令をロボットが音声認識で判断して、ものを取りにいったり等ロボットがその命令通りに動く競技です。 僕が担当しました。 Kaldi/pocketsphinxの音声認識の推論結果をROSトピック化して、大会時に実装したNLTK(自然言語処理ソフトウエアフレームワーク)とtaggerを用いた英語構文解析、英語照応解析(省略された単語や代名詞を推測するもの)し、音声命令を理解したことを示したことによって20点、全17チーム中5位という高得点を取りました!全17チーム中7チームが無得点である、難易度が高い競技でした。 taggerで単語の品詞を判定することができます。ときどき動詞を名詞と誤判定するので誤判定する部分はルールベースで修正しました。型変換の部分で少し苦労しました。 文章の意味抽出は英語の文型は標準は5つしかないため(SV,SVO,SVC,SVOO,SVOC)構文解析による意味抽出はとても簡単でした。 照応解析については、代名詞や省略が検知された場合、意味を抽出したリストを参照して前後に代名詞の参照元がないか検索するプログラムを製作しました。競技直前まで代名詞に命令を受けているロボット自身を参照する自己参照元(yourself)があることに気づかず、何とか直前に気づきプログラムを修正することができました。
一次予選結果
2次予選は上位10チームが進出することができます。当初は11位だったのですが、1チーム2次予選を辞退したため、繰り上がりで10位になり、2次予選に進出することができました!
次回予告
二次予選の競技について書きます!お楽しみに!

